oakink:A Large-scale Knowledge Repository for Understanding Hand-Object Interaction
如何和物体交互,分为两个部分来解决。第一个部分是oak,是以物体角度出发的(object-centric),解决应该和物体的哪个部分进行交互。第二个部分是ink,是以人类交互的角度出发的(human-centric),解决知道了应该和物体的哪个部分进行交互之后,人手应该怎么放置。
oak base
oak-object affordance knowledge,包括了1800个常见物体。物体记录了一些taxonomy和attribute,将物体分成了maniptool和functool。
- maniptool的物体有一个抓取部位和一个末端交互部位,比如说刀。
- functool的物体通常自己就可以实现功能,不需要和别的物体进行交互,比如说相机。
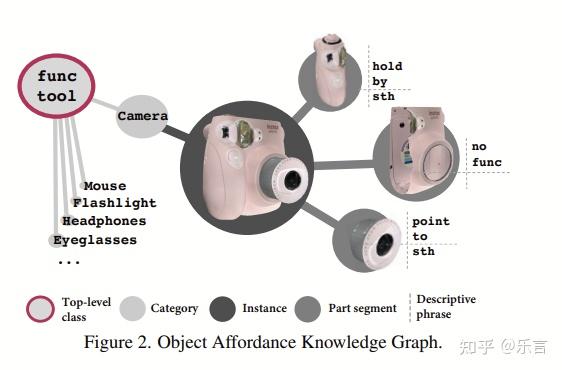
ink base
ink-interaction knowledge,ink database, 记录了人手和物体交互的策略,具有不同的操作意图和策略。采集了使用、握住、抬起、递出、接收五个动作。每次会记录物体位姿、手部位姿、接触区域、接触力分布。
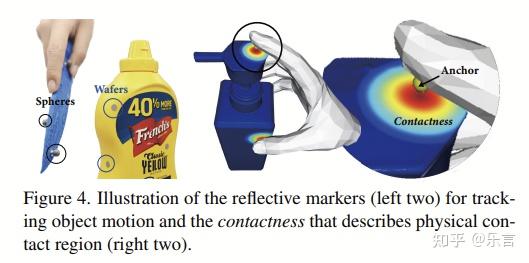
tlink
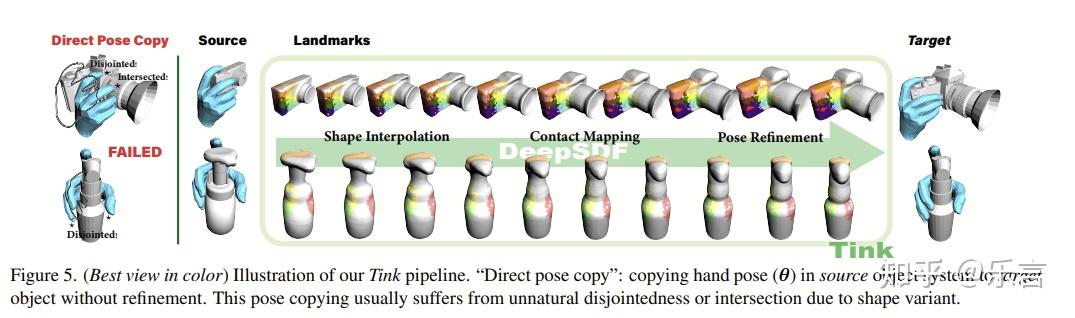
会做一些同类别的知识迁移,将一个物体的标注,应用到同类别的其他物体之上,具体流程如下:首先通过sdf表示物体,进行隐式插值。然后通过显式接触映射,将源物体的接触区域映射到目标物体。最后,做一些防止穿模的优化。
实验
解决了手部姿态预测、抓取预测、基于意图的抓取预测等问题。
oakink2:A Dataset of Bimanual Hands-Object Manipulation in
Complex Task Completion

分层任务表示
将操作任务抽象成三个层次:affordance -> primitive tasks -> complex tasks。
- 可供性层级(第一级):捕捉物体的潜在功能,例如
<contain, something>、<secure, something>或<heat, something>。这些代表了人类与物体交互的基本方式。 - 原始任务层级(第二级):代表基本的操控动作,如“拧开容器盖”或“倒出内容”。这些是更复杂活动的基本构建块。这里的affordance标注和primitive tasks并不一样,原子任务指的是整个执行的轨迹。
- 复杂任务层级(第三级):描述由多个原始任务组成的完整活动,例如“准备一碗热的甜水果茶”。这一层级包括显示原始任务之间关系的依赖图。
TaMF(Task-aware Motion Fullfillment)任务感知运动实现
关于如何做姿态生成:任务定义是根据描述+物体动态轨迹->手部轨迹预测。

CTC(Complex Task Completion复杂任务完成)
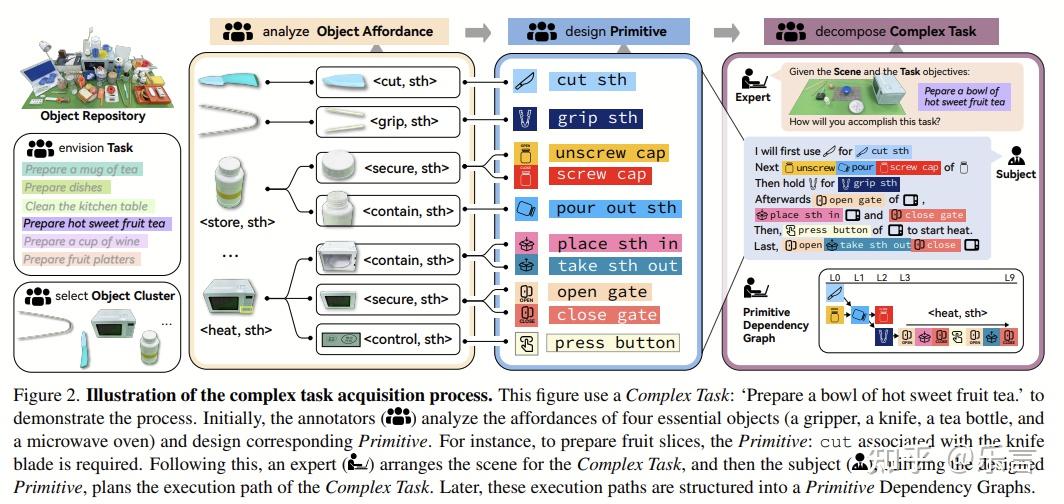

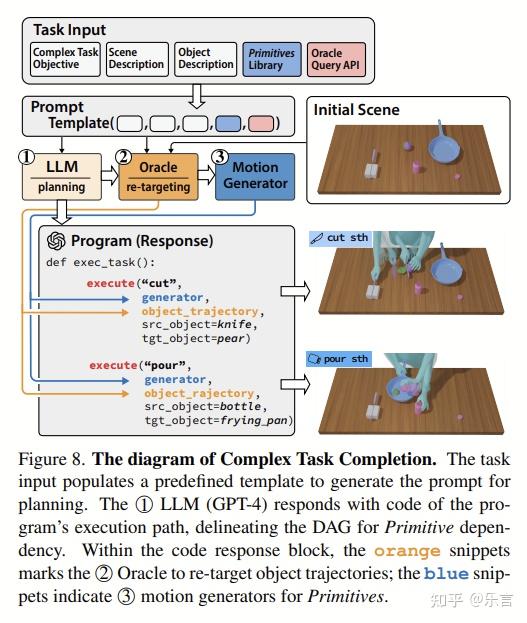
基于 LLM 的任务解释器:使用大型语言模型将复杂的任务目标分解为原始任务序列,生成序列图。
2. 物体轨迹检索:获取每个原始任务所需的物体运动轨迹。
3. 运动实现模型:生成可以执行原始任务并适当处理物体的双手手部运动。
Grasp as You Say:Language-guided Dexterous Grasp Generation
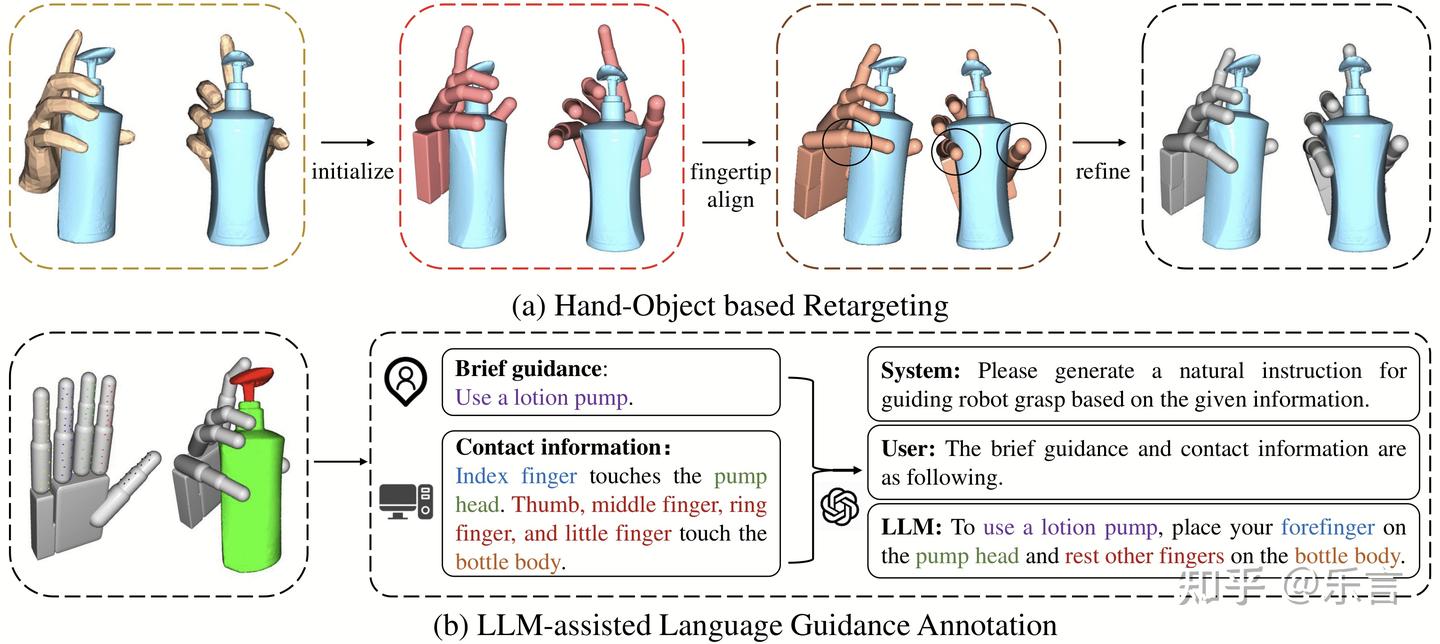
通过语言指导灵巧手抓取位姿的生成,更符合人实际上和物体的交互习惯。主要是观察到了这个研究方向的缺口,然后提供了数据+模型。
DexGYSNet:从一些人类演示数据中学的
MANIPTRANS: Efficient Dexterous Bimanual Manipulation Transfer via Residual Learning
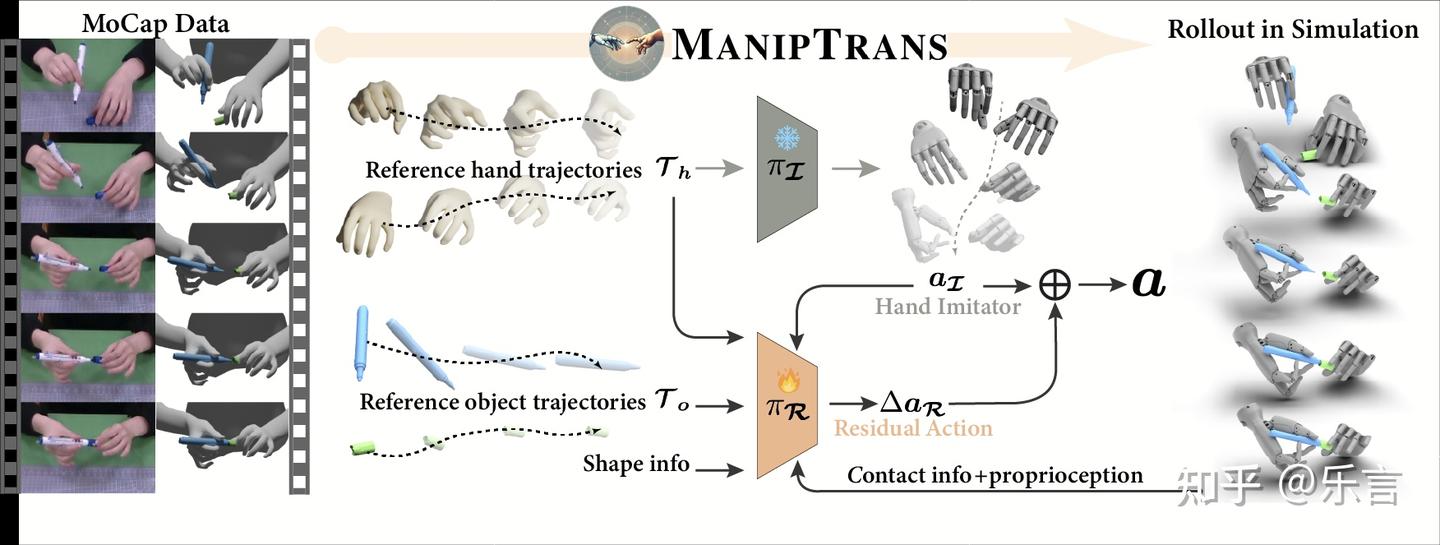
两阶段训练,一阶段模仿手部姿势,二阶段通过残差网络训练微调。将前文中的oakink2的手部数据,在模拟环境中转换到灵巧手上。
DexGraspVLA: A Vision-Language-Action Framework Towards General Dexterous Grasping
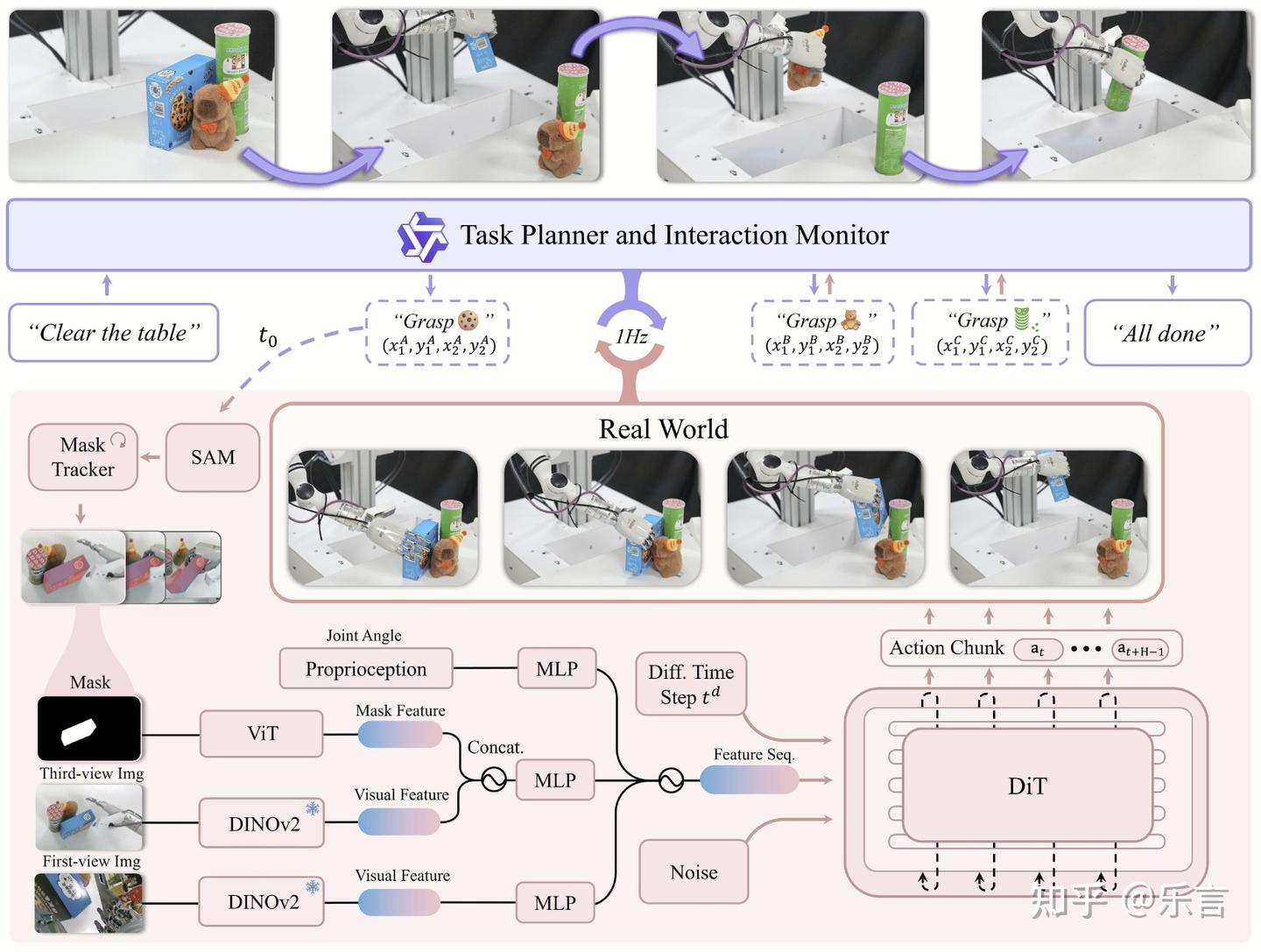
分层控制,planner + controller。planner出bbox,出mask,然后cutie进行跟踪。然后controller训一个dit来出action chunk。但我感觉主要是一个位置信息,就是知道往哪里抓,然后就知道怎么抓。看上去做得有点粗糙,不过确实也包括了不同的形状。
dexgrasp anything: towards Universal Robotic Dexterous Grasping with Physics Awareness
工作关键点在于“physics awareness”物理感知的优化,生成更符合物理的抓取位姿,
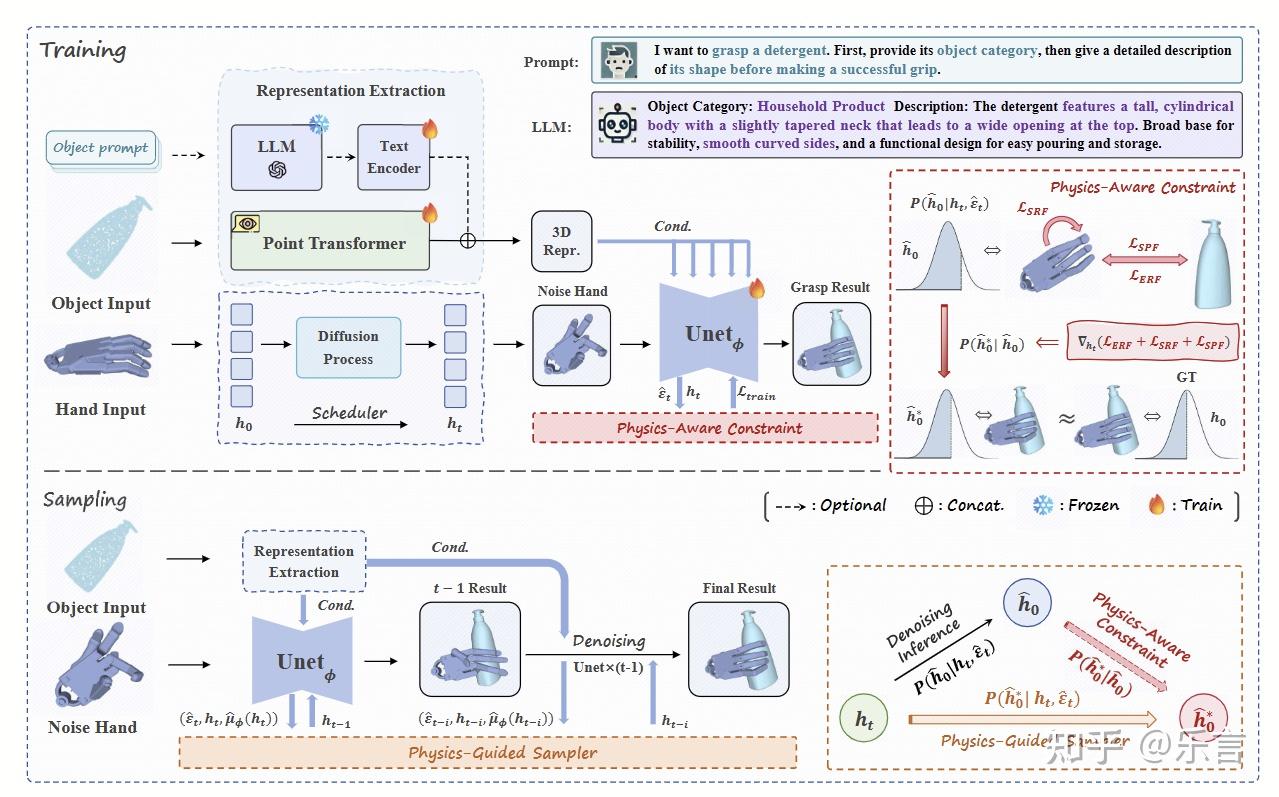
物理感知优化:表面拉力(SPF,确保灵巧手和物体接触)、外部穿透排斥力(ERF,防止手指穿透物体)、自身穿透排斥力(SRF,防止手指互相碰撞)。
扩散模型中的物理约束使用:在扩散模型的训练和采样中使用物理约束,训练时,让模型更倾向于输出干净的姿态,采样时,修复模型生成的不干净的姿态
语言约束:在训练和推理时作为condition。增强语言和姿态之间的相互影响力。(用了一个交叉注意力机制)